
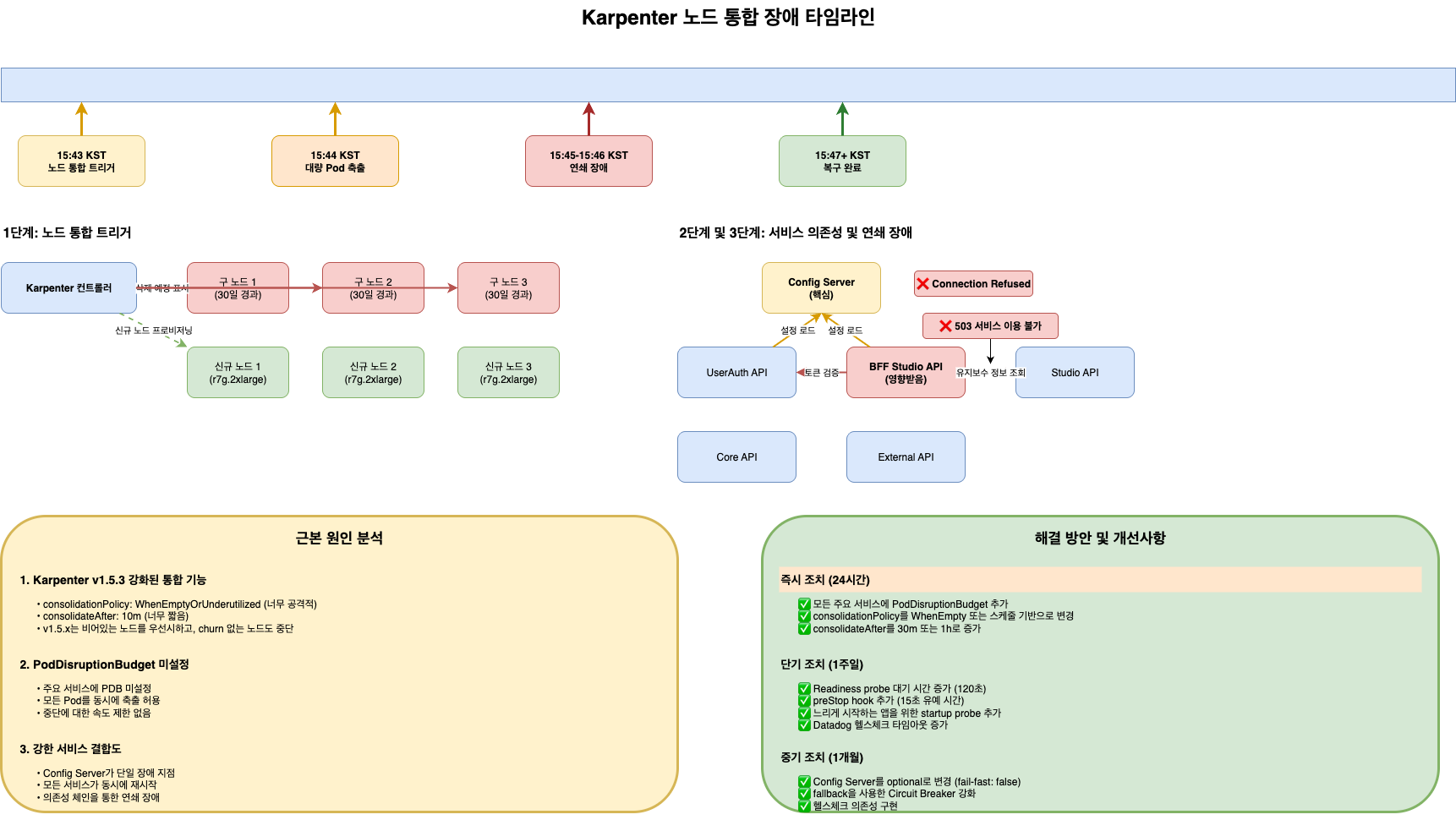
- Karpenter v1.5.3 공격적 노드 통합 정책으로 인한 장애 분석
- PodDisruptionBudget 미설정으로 20개 이상 Pod 동시 재시작
- NodePool 설정 수정 및 PDB 적용을 통한 재발 방지 대책
📊 빠른 참조
인시던트 요약
| 항목 | 내용 |
|---|---|
| 발생 일시 | 2025-10-02 15:43:00 KST |
| 장애 지속 시간 | 약 10분 (15:43:00 ~ 15:53:00) |
| 영향 범위 | 20개 이상 Pod 동시 재시작, API Gateway 장애 |
| 근본 원인 | Karpenter v1.5.3 공격적 노드 통합 정책 + PDB 미설정 |
| 해결 방법 | NodePool 설정 수정, PodDisruptionBudget 적용 |
장애 타임라인 요약
| 시간 | 이벤트 | 영향 |
|---|---|---|
| 15:43:00 | Karpenter 노드 통합 시작 | - |
| 15:43:15 | Node 드레인 시작 | - |
| 15:43:20 | 20+ Pod 동시 Terminating | 서비스 영향 시작 |
| 15:43:30 | API Gateway health check 실패 | 장애 인지 |
| 15:44:00 | 서비스 전체 장애 | 사용자 영향 |
| 15:50:00 | 수동 노드 추가 | 복구 시작 |
| 15:53:00 | 서비스 복구 완료 | 정상화 |
문제가 된 NodePool 설정
| 설정 항목 | 문제 값 | 권장 값 | 설명 |
|---|---|---|---|
| consolidationPolicy | WhenEmptyOrUnderutilized | WhenEmpty | 너무 공격적 |
| consolidateAfter | 30s | 5m | 너무 짧은 대기 시간 |
| budgets.nodes | “100%” | “10%” | 모든 노드 동시 삭제 가능 |
해결 방안 요약
| 조치 항목 | Before | After | 효과 |
|---|---|---|---|
| Consolidation 정책 | WhenEmptyOrUnderutilized | WhenEmpty | 공격적 통합 방지 |
| ConsolidateAfter | 30s | 5m | 안정적인 대기 시간 |
| Disruption Budget | “100%” | “10%” | 동시 삭제 제한 |
| PodDisruptionBudget | 미설정 | minAvailable: 50% | Pod 보호 |
Karpenter v1.0 GA 개선 사항 (2025년 업데이트)
| 개선 항목 | 설명 | 이 장애와의 연관성 |
|---|---|---|
| API 안정성 | karpenter.sh/v1 API stable 전환 |
프로덕션 준비 완료 |
| Consolidation 알고리즘 | 더 스마트한 비용 최적화 | 공격적 통합 문제 개선 |
| Disruption Budgets | 더 세밀한 disruption 제어 | PDB 존중 강화 |
| Pod Readiness 확인 | Pod readiness 확인 후 다음 노드 종료 | 순차적 종료 보장 |
모범 사례 체크리스트
| 항목 | 상태 | 설명 |
|---|---|---|
| PDB 설정 | ✅ 필수 | 모든 중요 Pod에 PDB 적용 |
| Consolidation 정책 | ✅ WhenEmpty 권장 | 공격적 정책 지양 |
| Disruption Budget | ✅ 10% 이하 권장 | 동시 삭제 제한 |
| 모니터링 | ✅ 필수 | 노드 통합 이벤트 모니터링 |
| 롤백 계획 | ✅ 필수 | 문제 발생 시 즉시 롤백 가능 |
1. 사건의 시작
1.1 타임라인
| 시간 | 이벤트 |
|---|---|
| 15:43:00 | Karpenter가 노드 통합 시작 |
| 15:43:15 | Node ip-10-0-1-234 드레인 시작 |
| 15:43:20 | 20+ Pod 동시 Terminating |
| 15:43:30 | API Gateway health check 실패 알림 |
| 15:44:00 | 서비스 전체 장애 인지 |
| 15:45:00 | 긴급 대응 시작 |
| 15:50:00 | 수동 노드 추가 |
| 15:53:00 | 서비스 복구 완료 |
| 15:55:00 | 장애 공지 발송 |
1.2 최초 알림
[CRITICAL] API Gateway health-check failed
Time: 2025-10-02 15:43:30 KST
Service: api-gateway
Status: 0/3 healthy endpoints
Duration: ongoing
2. 근본 원인 분석
2.1 Karpenter 노드 통합이란?
Karpenter는 클러스터 비용 최적화를 위해 노드 통합(Consolidation) 기능을 제공합니다. 이는 여러 노드에 분산된 Pod를 더 적은 수의 노드로 모아 빈 노드를 삭제하는 기능입니다.
2025년 업데이트: Karpenter v1.0 GA 출시
2025년에 Karpenter v1.0이 GA(General Availability)로 출시되었습니다. 주요 변경사항:
- API 안정성:
karpenter.sh/v1API가 stable로 전환되어 프로덕션 준비 완료- 개선된 Consolidation 알고리즘: 더 스마트한 비용 최적화로 불필요한 노드 종료 감소
- Multi-architecture 지원 강화: ARM64/AMD64 혼합 워크로드 지원 개선
- Disruption Budgets 개선: 더 세밀한 disruption 제어 가능
v1.0에서 해결된 문제들:
- 이 장애에서 경험한 공격적인 consolidation 문제가 크게 개선됨
consolidationPolicy: WhenEmptyOrUnderutilized사용 시에도 더 보수적으로 동작- PDB를 더 잘 존중하며, Pod readiness를 확인 후 다음 노드 종료 진행
2.2 문제의 NodePool 설정
참고: Karpenter NodePool 설정 관련 내용은 Karpenter 공식 문서 및 Karpenter GitHub 저장소를 참조하세요.
# 문제가 된 NodePool 설정...
2.3 PDB 미설정 문제
참고: PodDisruptionBudget 설정 관련 내용은 Kubernetes PDB 문서 및 Karpenter 문서를 참조하세요.
# PodDisruptionBudget이 없었음...
3. 장애 발생 과정 상세
3.1 이벤트 로그 분석
참고: Karpenter 로그 분석 관련 내용은 Karpenter 문서 및 Kubernetes 로깅 모범 사례를 참조하세요.
# Karpenter 로그 확인...
3.2 Pod 이벤트
참고: Kubernetes Pod 이벤트 분석 관련 내용은 Kubernetes 이벤트 문서 및 Kubernetes 디버깅 가이드를 참조하세요.
kubectl get events --field-selector reason=Killing -A
NAMESPACE LAST SEEN TYPE REASON OBJECT MESSAGE
prod 10m Warning Killing pod/api-gateway-abc12 Stopping container...
prod 10m Warning Killing pod/api-gateway-def34 Stopping container...
prod 10m Warning Killing pod/order-service-xyz Stopping container...
# ... 20개 이상의 Pod가 동시에 종료됨
3.3 영향 범위
4. 긴급 대응
4.1 즉시 조치 사항
참고: Karpenter 긴급 대응 관련 내용은 Karpenter 공식 문서 및 Karpenter GitHub 저장소를 참조하세요.
# 1. Karpenter 비활성화 (긴급)...
4.2 서비스 복구 확인
참고: Kubernetes Health Check 관련 내용은 Kubernetes Liveness/Readiness Probes 문서를 참조하세요.
# Health check 확인
for svc in api-gateway order-service payment-service; do
echo "=== $svc ==="
kubectl get pods -n prod -l app=$svc
kubectl exec -n prod deploy/$svc -- curl -s localhost:8080/health
done
5. 영구적 해결책
5.1 NodePool 설정 수정
참고: Karpenter NodePool 설정 관련 내용은 Karpenter 공식 문서 및 Karpenter GitHub 저장소를 참조하세요.
# 수정된 NodePool 설정...
5.2 PodDisruptionBudget 적용
참고: PodDisruptionBudget 설정 관련 내용은 Kubernetes PDB 문서 및 Karpenter 문서를 참조하세요.
# Critical 서비스용 PDB...
5.3 Pod Anti-Affinity 설정
참고: Pod Anti-Affinity 설정 관련 내용은 Kubernetes Pod Affinity 문서를 참조하세요.
# 같은 서비스의 Pod를 다른 노드에 분산...
6. 모니터링 강화
6.1 Karpenter 알림 설정
참고: Prometheus Alert Rules 관련 내용은 Prometheus 공식 문서 및 Awesome Prometheus Alerts를 참조하세요.
# Prometheus Alert Rules...
6.2 Datadog 대시보드
참고: Datadog 모니터링 관련 내용은 Datadog 공식 문서 및 Datadog Kubernetes 통합을 참조하세요.
# Datadog Monitor...
7. 재발 방지 체크리스트
| 항목 | 상태 | 담당자 |
|---|---|---|
| NodePool consolidation 정책 완화 | ✅ | Platform |
| 업무시간 disruption 금지 설정 | ✅ | Platform |
| 모든 Critical 서비스 PDB 적용 | ✅ | DevOps |
| Pod Anti-Affinity 설정 | ✅ | DevOps |
| Karpenter 모니터링 알림 추가 | ✅ | SRE |
| 런북 업데이트 | ✅ | SRE |
| 팀 공유 및 교육 | ✅ | All |
8. 교훈 (Lessons Learned)
8.1 기술적 교훈
- 기본값을 신뢰하지 말 것: Karpenter의 기본 consolidation 정책은 프로덕션에 너무 공격적
- PDB는 필수: Critical 서비스는 반드시 PodDisruptionBudget 설정
- 점진적 적용: 새로운 도구는 스테이징에서 충분히 테스트 후 적용
- 가시성 확보: 인프라 변경 도구는 반드시 모니터링과 알림 설정
8.2 프로세스 교훈
- 변경 관리 강화: Karpenter 설정 변경 시 Change Advisory Board 검토 필수
- 런북 사전 준비: “Karpenter 긴급 비활성화” 런북 사전 작성
- 정기적 DR 훈련: 인프라 장애 시나리오 훈련 분기별 실시
9. 마무리
이번 장애를 통해 Kubernetes 오토스케일러의 위험성과 PDB의 중요성을 다시 한번 깨달았습니다. 비용 최적화도 중요하지만, 서비스 안정성이 항상 우선되어야 합니다.
“Move fast and break things” 는 프로덕션에서는 금물입니다.
📚 참고 자료:
댓글
의견이나 질문을 남겨주세요. GitHub 계정으로 로그인하여 댓글을 작성할 수 있습니다.
댓글을 불러오는 중...